lightrush
- 7 Posts
- 96 Comments


B350 isn’t a very fast chipset to begin with
For sure.
I’m willing to bet the CPU in such a motherboard isn’t exactly current-gen either.
Reasonable bet, but it’s a Ryzen 9 5950X with 64GB of RAM. I’m pretty proud of how far I’ve managed to stretch this board. 😆 At this point I’m waiting for blown caps, but the case temp is pretty low so it may end up trucking along for surprisingly long time.
Are you sure you’re even running at PCIe 3.0 speeds too?
So given the CPU, it should be PCIe 3.0, but that doesn’t remove any of the queues/scheduling suspicions for the chipset.
I’m now replicating data out of this pool and the read load looks perfectly balanced. Bandwidth’s fine too. I think I have no choice but to benchmark the disks individually outside of ZFS once I’m done with this operation in order to figure out whether any show problems. If not, they’ll go in the spares bin.
I put the low IOPS disk in a good USB 3 enclosure, hooked to an on-CPU USB controller. Now things are flipped:
capacity operations bandwidth
pool alloc free read write read write
------------------------------------ ----- ----- ----- ----- ----- -----
storage-volume-backup 12.6T 3.74T 0 563 0 293M
mirror-0 12.6T 3.74T 0 563 0 293M
wwn-0x5000c500e8736faf - - 0 406 0 146M
wwn-0x5000c500e8737337 - - 0 156 0 146M
You might be right about the link problem.

Looking at the B350 diagram, the whole chipset is hooked via PCIe 3.0 x4 link to the CPU. The other pool (the source) is hooked via USB controller on the chipset. The SATA controller is also on the chipset so it also shares the chipset-CPU link. I’m pretty sure I’m also using all the PCIe links the chipset provides for SSDs. So that’s 4GB/s total for the whole chipset. Now I’m probably not saturating the whole link, in this particular workload, but perhaps there’s might be another related bottleneck.
Turns out the on-CPU SATA controller isn’t available when the NVMe slot is used. 🫢 Swapped SATA ports, no diff. Put the low IOPS disk in a good USB 3 enclosure, hooked to an on-CPU USB controller. Now things are flipped:
capacity operations bandwidth
pool alloc free read write read write
------------------------------------ ----- ----- ----- ----- ----- -----
storage-volume-backup 12.6T 3.74T 0 563 0 293M
mirror-0 12.6T 3.74T 0 563 0 293M
wwn-0x5000c500e8736faf - - 0 406 0 146M
wwn-0x5000c500e8737337 - - 0 156 0 146M
Interesting. SMART looks pristine on both drives. Brand new drives - Exos X22. Doesn’t mean there isn’t an impending problem of course. I might try shuffling the links to see if that changes the behaviour on the suggestions of the other comment. Both are currently hooked to an AMD B350 chipset SATA controller. There are two ports that should be hooked to the on-CPU SATA controller. I imagine the two SATA controllers don’t share bandwidth. I’ll try putting one disk on the on-CPU controller.

- •
- discourse.practicalzfs.com
- •
- 2M
- •

- Lenovo ThinkCentre / Dell OptiPlex USFF machine like the M710q.
- Secondary NVMe or SATA SSD for a RAID1 mirror
- Use LVMRAID for this. It uses mdraid underneath but it’s easier to manage
- External USB disks for storage
- WD Elements generally work well when well ventilated
- OWC Mercury Elite Pro Quad has a very well implemented USB path and has been problem-free in my testing
- Debian / Ubuntu LTS
- ZFS for the disk storage
- Backups may require a second copy or similar of this setup so keep that in mind when thinking about the storage space and cost
Here’s a visual inspiration:

- •
- 7M
- •
Here’s the box test thread if you’re curious. 😊
This article provides some context. Now I do have the latest firmware which should have these fixes but they don’t seem to be foolproof. I’ve seen reports around the web that the firmware improves things but doesn’t completely eliminate them.
If you’ve seen devices disconnecting and reconnecting on occasion, it could be it.
I’ve been on the USB train since 2019.
You’re exactly right, you gotta get devices with good USB-to-SATA chipsets, and you gotta keep them cool.
I’ve been using a mix of WD Elements, WD MyBook and StarTech/Vantec enclosures (ASM1351). I’ve had to cool all the chipsets on WD because they like bolt the PCBs straight to the drive so it heats up from it.
From all my testing I’ve discovered that:
- ASM1351 and ASM235CM are generally problem-free, but the former needs passive cooling if close to a disk. A small heatsink adhered with standard double-sided heat conductive tape is good enough.
- Host controllers matter too. Intel is generally problem-free. So is VIA. AMD has some issues on the CPU side on some models which are still not fully solved.
I like this box in particular because it uses a very straightforward design. It’s got 4x ASM235CM with cooling connected to a VIA hub. It’s got a built-in power supply, fan, it even comes with good cables. It fixes a lot of the system variables to known good values. You’re left with connecting it to a good USB host controller.
WD PCB on disk

I thought about it, but it typically requires extra PCIe cards that I can’t rely on as there’s no space in one of the machines and no PCIe slots in the other. That’s why I did a careful search till I stumbled upon this particular enclosure and then I tested one with ZFS for over a week before buying the rest.
Thanks for the warning ⚠️🙏
This isn’t my first rodeo with ZFS on USB. I’ve been running USB for a few years now. Recently I ran this particular box through a battery of tests and I’m reasonably confident that with my particular set of hardware it’ll be fine. It passed everything I threw at it, once connected to a good port on my machine. But you’re generally right and as you can see I discussed that in the testing thread, and I encountered some issues that I managed to solve. If you think I’ve missed something specific - let me know! 😊
- 8x 8TB in a set of 2, some shucked WDs, some IronWolfs
- 5x 16TB in a set of 2, “recertified” WDs from serverpartdeals.com

I see a number of dual-output PSUs on Mouser that will probably fit well if this goes. For example.
440 pounds is insane, agreed. 😂
Yeah I get it then. So it depends on whether one has PCIe slots available, 3.5" bays in the case, whether they can change the case if full, etc. It could totally make sense to do under certain conditions. In my case there’s no space in my PC case and I don’t have any PCIe slots left. In addition, I have an off-site machine that’s an USFF PC which has no PCIe slots or SATA ports. It’s only available connectivity is USB. So in my case USB is what I can work with. As long as it isn’t exorbitantly expensive, a USB solution has flexibility in this regard. I would have never paid 440 pounds for this if that was the price. I’d have stayed with single enclosures nailed to a wooden board and added a USB hub. 🥹 Which is how they used to be:

Please elaborate.
What I parse that you’re talking about is a PCIe SATA host controller and a box for the disks. Prior to landing on the OWC, I looked at QNAP’s 4-bay solution that does this - the TL-D400S. That can be found around the $300 mark. The OWC is $220 from the source. That’s roughly equivalent to 4 of StarTech’s enclosures that use the same chipset.
I wasn’t able to reach it for a top-down visual through the back and so I don’t have pics of it other than the side view already attached. I’ll try disassembling it further sometime today, once the ZFS scrub completes.
Luckily, the PSU is connected to the main board via standard molex. If the built-in one blows up, you could replace it with any ATX PSU, large, small (FlexATX, etc), or one of those power bricks that spit out a 5V/12V molex. Whether you can stuff it in or not.
I was wondering what would be better for discoverability, to write this in a blog post, on GitHub, then link it here, or to just write it here. Turns out Google’s crawling Lemmy quite actively. This shows up within the first 10-15 results for “USB DAS ZFS”:
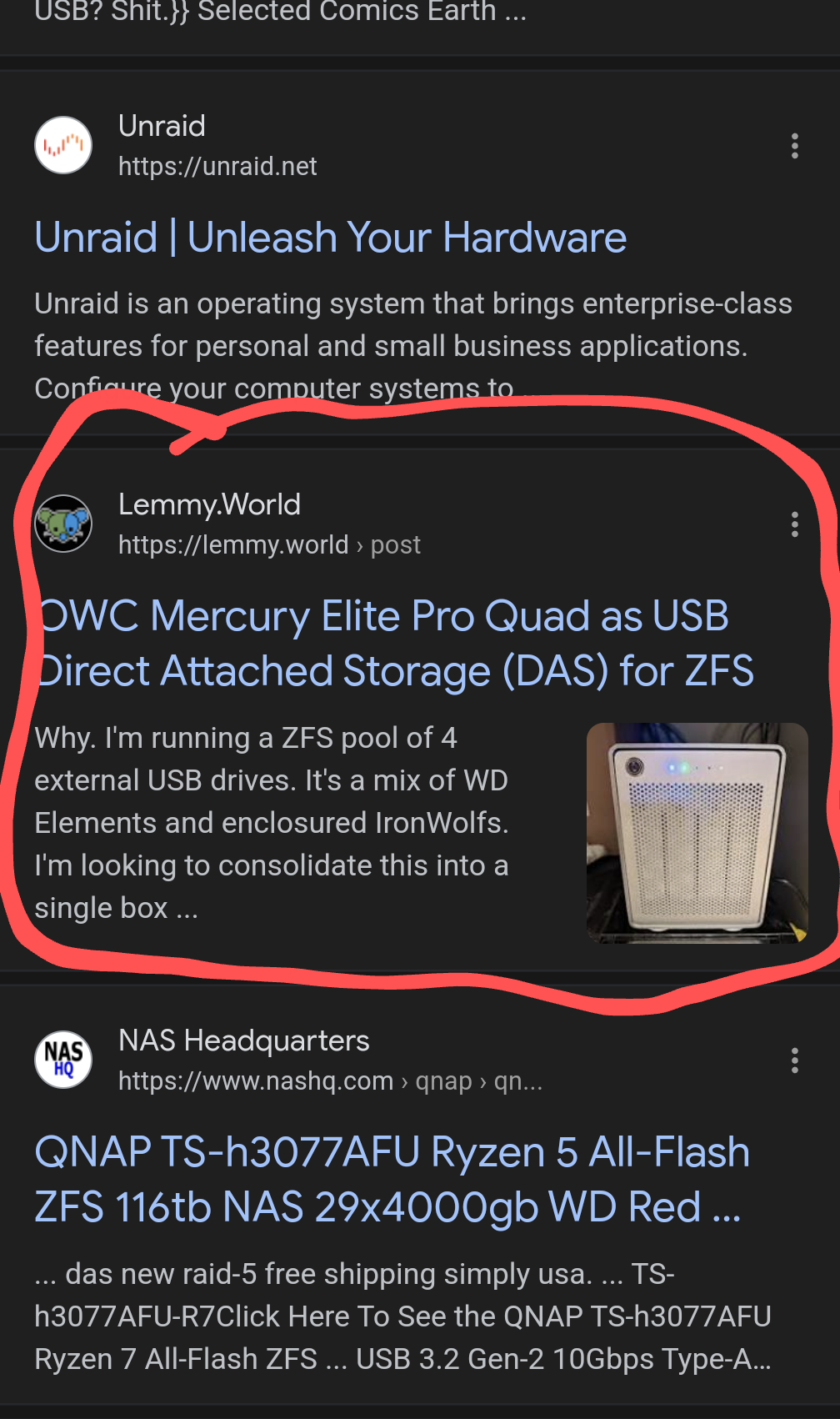
It appears that Lemmy is already a good place for writing stuff like this. ☺️
- •
- lemmy.ca
- •
- 7M
- •

- •
- youtube.com
- •
- 9M
- •


Feels like this will benefit from some sort of fuzzy deduplication in the pictrs storage. I bet there are a lot of similar pics in there. E.g. if one pic or a gif is very similar to another, say just different quality or size, or compression, it should keep only one copy. It might already do this for the same files uploaded by different people as those can be compared trivially via hashing, but I doubt it does similarity based deduplication.
Exactly. There are obvious problems with this conundrum and the government’s move is not ideal but then the situation we’re in is also not ideal. The implications of leaving it unmitigated are eating into our democracy and without a functioning democracy, there’s no functioning world wide web. And so as a firm supporter of the WWW, I find myself having to stick for our government and our media oligopoly (🤢) on this one even if it’s not ideal from the WWW lens. It feels a bit like chemotherapy. We have to do it even if we harm some systems because otherwise many more systems will go. 🤷
- •
- archive.ph
- •
- 1Y
- •


I think the board has reached the end of the road. 😅