
☆ Yσɠƚԋσʂ ☆
- 301 Posts
- 224 Comments



 English
English- •
- media.mas.to
- •
- 3d
- •



I think you’re on to something. Given how software is generally built to the lowest standard possible, there are more and more exploits piling on as a result. The details of any modern tech stack is far beyond human comprehension. It’s just not possible to meaningfully audit all the code and all the different interactions within it. The whole thing is just a giant house of cards.
This is the curse of working in tech. As long as things are working smoothly from customer perspective then the pleas to spend the time to deal with the tech debt are ignored. Yet, when enough debt piles up and things start breaking then it’s the people who’ve been warning about the problems the whole time who get blamed.
When a project is developed for a while, a lot of initial design decisions can become invalidated as business needs evolve. New features have to be added, and in many cases they go against original assumptions about how the project would be used. At that point you have to start making hacks and kludging new features in. This creates a lot of special cases and surprising behaviors making overall project brittle and hard to maintain. That’s what’s known as tech debt.
In an ideal world you would have time to do proper redesign to accommodate new features, clean up problems as you go, and so on. However, in reality there’s usually just not enough time to do any of that so people just pile on features at the cost of overall development becoming harder and more error prone. This is a great discussion on the subject incidentally https://medium.com/@wm/the-generation-ship-model-of-software-development-5ef89a74854b

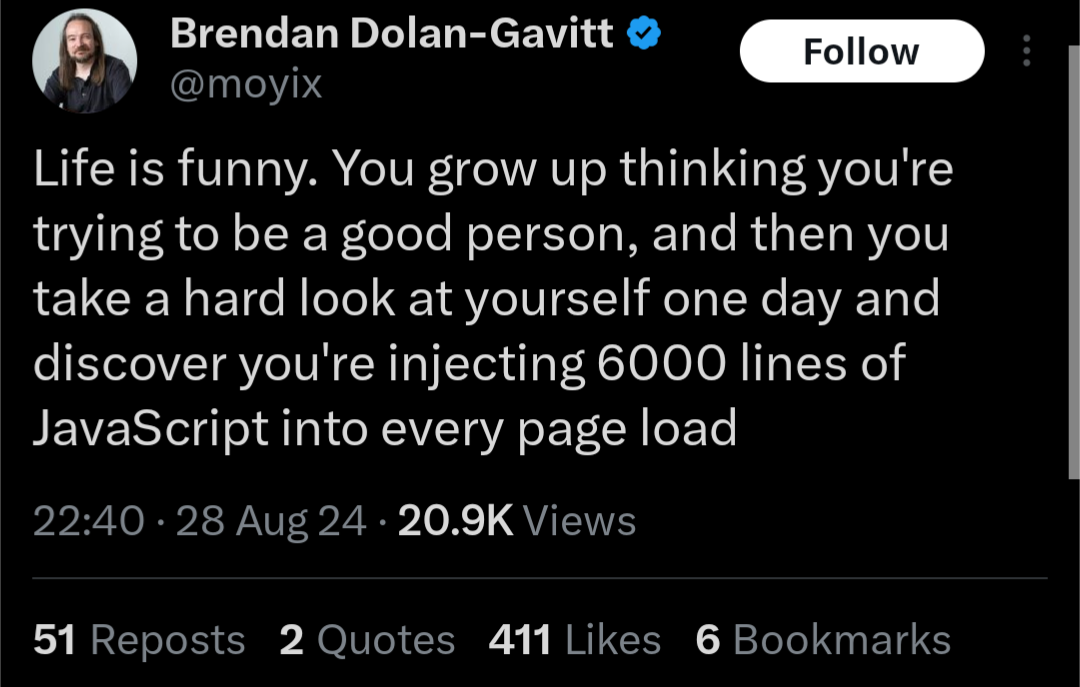




here’s a good overview of what happened https://www.thestack.technology/crowstrike-null-pointer-blamed-rca/



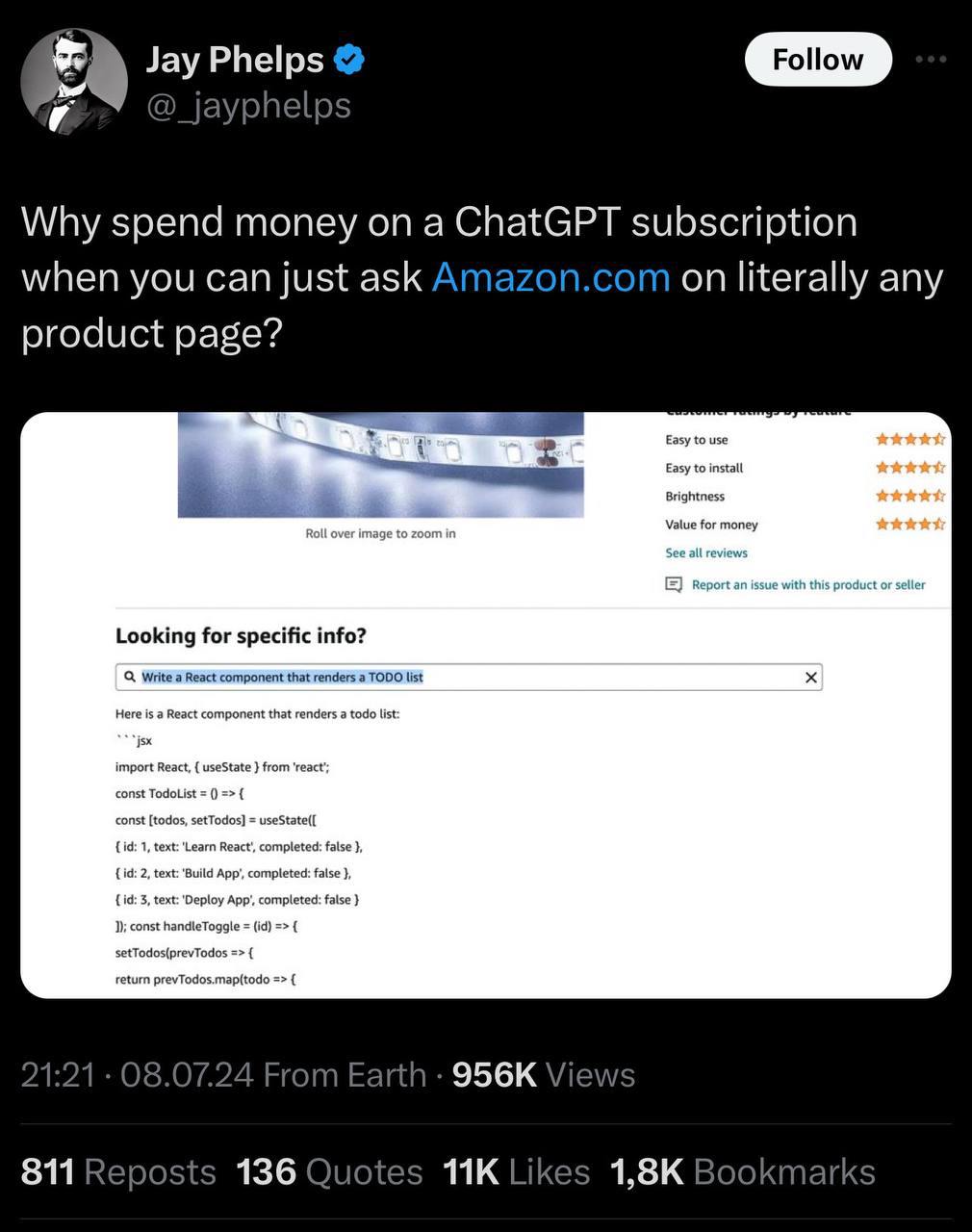
“I have discovered a truly marvelous demonstration of this proposition that this margin is too narrow to contain.” https://www.joh.cam.ac.uk/library/special_collections/early_books/fermat.htm#:~:text=When reviewing his copy of,to fit in the margin

I really like this approach for doing non trivial regex https://github.com/VerbalExpressions
const tester = VerEx()
.startOfLine()
.then('http')
.maybe('s')
.then('://')
.maybe('www.')
.anythingBut(' ')
.endOfLine();







- •
- media.mas.to
- •
- 4M
- •
- •
- media.mas.to
- •
- 4M
- •




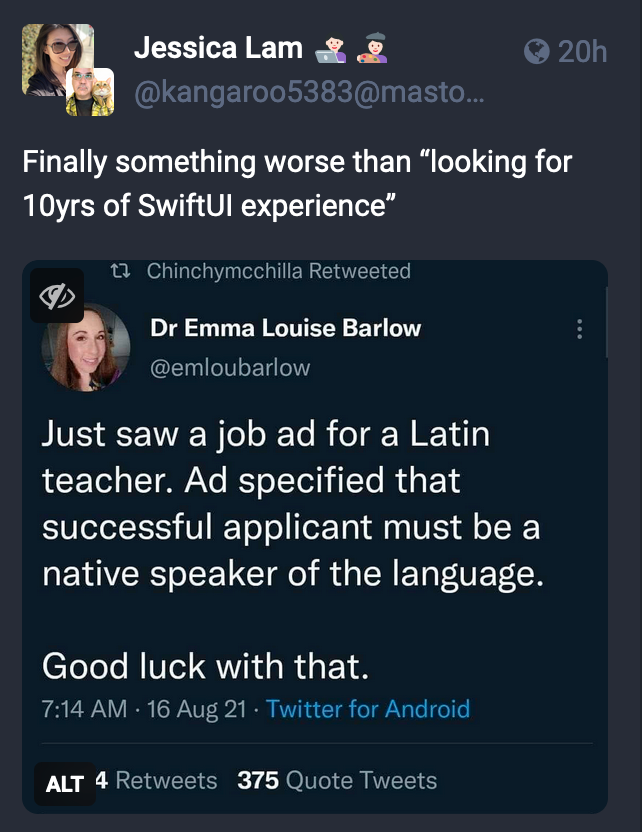
unless it’s been a decade since 2019 :) https://en.wikipedia.org/wiki/SwiftUI
- •
- lemmy.ml
- •
- 4M
- •
I very much agree with designing things in style of microservices in terms of having isolated components that can be reasoned about independently. In my experience, this is the only way to keep large projects manageable. Incidentally, this is also why I’ve come to appreciate functional approach with immutability as the default. It makes it much easier to write largely stateless code where all the IO happens at the edges, and then you just pass your context around explicitly through pure functions.
Nowhere did I say you shouldn’t have a staging environment. However, if you can develop and test changes locally then by the time it goes to staging, the code should already be in good shape most of the time. Staging is like your guardrail, it shouldn’t be part of your main dev loop.
Meanwhile, not sure what the issue is with running a monolith locally. The reality is that even large applications aren’t actually that big in absolute terms. Having to run a bunch of services locally to test things end to end is certainly not any easier either.

The main problem with microservice architecture is around orchestration. People tend to downplay the complexity involved in making sure all the services are running and talking to each other. On top of that, you have a lot of overhead in having to make endpoints and client calls along with all the security concerns where it would just be a simple function call otherwise. Finally, services often end up talking to the same database, and then you just end up with your shared state in the db which largely defeats the point.
This approach has some benefits to it. You can write different services in different languages. Different teams can be responsible for maintaining each service. The scope of the code can be kept contained reducing mental overhead. However, that has to be weighed against the downsides as well. At the end of the day, whether this is the right architecture really depends on the problem being solved, and the team solving it.
I’ve worked on projects where microservices resulted in a complete disaster and that ended up being rewritten as monoliths, and ones where splitting things up worked fairly well.
What I’ve found works best is having services that encapsulate some particular functionality that’s context free. For example, a service that can generate PDFs for reports that can be reused by a bunch of apps that can send it some Markdown and get a PDF back. Having a service bus of such services gives you a bunch of reusable components, and since they don’t have any business logic in them, you don’t have to touch them often. However, any code that deals with a particular business workflow is much better to keep all in one place.




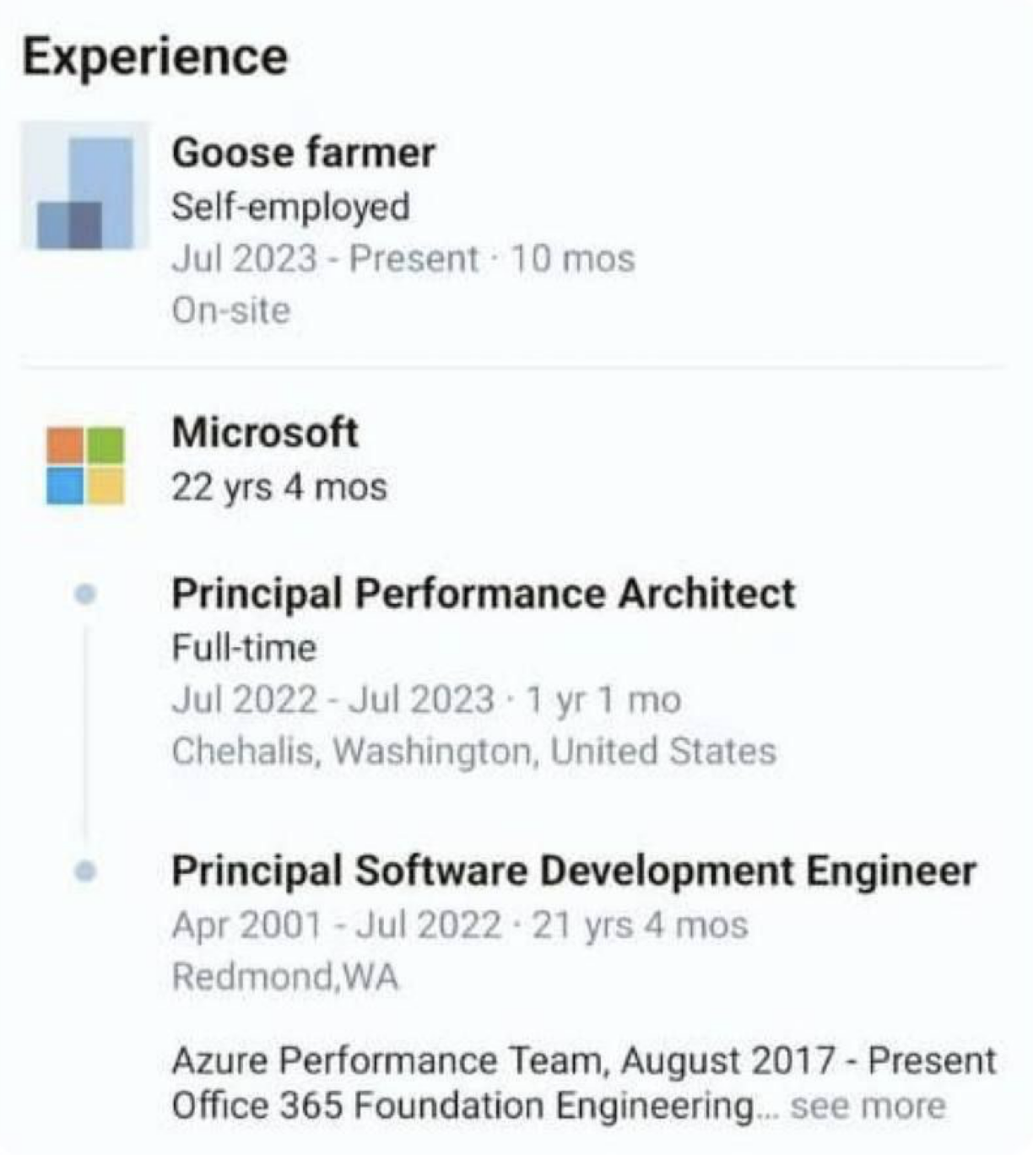

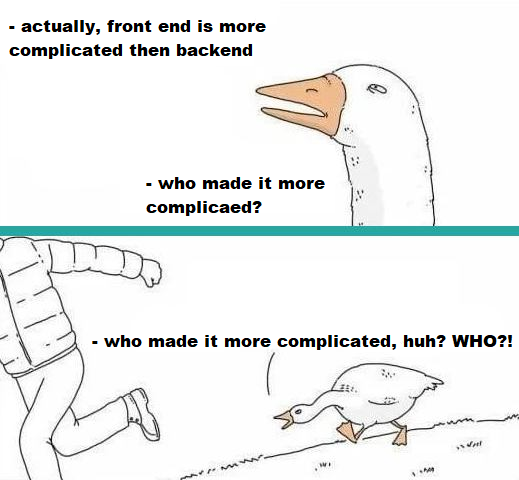

{kind=link}
and like 4 of them aren’t birds but venomous spiders trying to disguise themselves and murder you