In this tutorial, I will be using an Ubuntu to demonstrate the process.
While there is a project called Openbooks that can automate this process, I will be showing you how to do it manually because I’ve found Openbooks to be unreliable.
We will be using HexChat for this tutorial, but feel free to use an alternative client if you prefer. The process will remain the same regardless of the client you choose. As a side note, I’ve completed writing this guide and have found that HexChat is no longer supported. Instead, I recommend using Polari (for GNOME), Pidgin, or Konversation (for KDE). In fact, I’ve replaced the screenshots of connecting to the server with instructions on how to do it in Konversation, as it’s the most similar to HexChat. However, Pidgin and Polari are also suitable alternatives that will work just as well.
Launch your IRC client.
Click on “New…”
In the Server field, enter irc.irchighway.net and ensure the port number is set to 6667. Make sure to leave the SSL checkbox unchecked. Once you’ve entered the details, click OK to save the changes. Then, navigate to the Server list interface and click the “Connect” button.
If you’re having trouble connecting, it’s possible that your IP address has been blocked. This is more likely if you’re using a VPN, Tor, or I2P.
Type /join #ebooks in the chat box
To search for a specific eBook, type @search followed by the title or keywords of the book you’re looking for. For example, if you’re interested in finding a book from the Harry Potter series, you can type @search Harry Potter.
Try to find the book with just one search to avoid overwhelming the servers.
A window will appear; simply click the “Accept” button. Once you do, a zip file will be downloaded and saved to your default download folder.
Extract the text file from the zip file, and then open the text file.
Identify the book you want to obtain, and then copy the corresponding line of text. In my case, I want to get “Harry Potter and the Chamber of Secrets”, so I will copy the line !DeathCookie J K Rowling - Harry Potter and the Chamber of Secrets.epub and paste it into the chat box.
Click on the file, and then click the “Accept” button. The file will then be downloaded to your default downloads folder, and you’ll have it.
The IRC bots that run these sharing channels will crap themselves if hit with any kind of automation. Many/most have limited bandwidth and use a queueing system that only serves one or two downloads at a time and a small queue (it varies, some may have a 10 slot queue, some may have 50 or 100).
You can automate this; but you have to make sure that the automation you create is going to respect the ratelimits. I’d recommend something simple like using a command alias or short script written for your specific IRC client.
It’s what I used to do with that sort of thing; and there are plenty of well known Open Source scripts in the wild as well
As an example; I would use mIRC with it’s scripting system and write my own event trigger scripts to automatically request, wait for and then accept the DCC chat requests and route them appropriately in the interface. There were also scripts that helped with getting the lists; unpacking them, and displaying those lists in my client…so I didn’t have to extract the text from the zip myself, and could select what I needed from the bot.
All of this was lightweight automation that was intended not to flood the bot with commands and fed into command queueing modules that let the bots have time to process.
Sometimes in those days you could get actually (+b)anned, Auto/KILL’ed or /(G/K):LINE’ed for causing a bot to crash…so you had to be careful and respectful with regard to scripts.
TL;DR; know your bot, source channel & network rules, and write your own scripts for safety or read any scripts you import in carefully and understand what they’re doing.
Man, I’m getting flashbacks to my days running omenserve on undernet. I had no idea people were still doing this! How does the content compare to places like Anna’s archive these days?
Ah, good to know. Back in my day, when we had to walk a hundred miles to school in the snow, up hill both ways, IRC was the only place to get ebooks. I’m guessing it’s just the old users clinging on now.
I never did that, my connection was too slow to want to take up someone’s DCC slot for like a day to get an entire movie. Remember all the frustrating idiots who would share .lit files, but forget to remove the DRM from them?
In most sharing channels you could possibly just report those to the channel ops (@/&/!/~) and get them kicked or devoiced (removing their (+ or %) state depending on the channel)
I don’t know any channel that would put up with people who wasted your time with DRM’ed files back in the day. It’s less problematic now yes; but still something they don’t want people doing…since you have to be signed in as the purchasing account to de-drm something.
You are not logged in. However you can subscribe from another Fediverse account, for example Lemmy or Mastodon. To do this, paste the following into the search field of your instance: !piracy@lemmy.dbzer0.com
⚓ Dedicated to the discussion of digital piracy, including ethical problems and legal advancements.
 Click on “New…”
Click on “New…”
 To search for a specific eBook, type @search followed by the title or keywords of the book you’re looking for. For example, if you’re interested in finding a book from the Harry Potter series, you can type @search Harry Potter.
To search for a specific eBook, type @search followed by the title or keywords of the book you’re looking for. For example, if you’re interested in finding a book from the Harry Potter series, you can type @search Harry Potter.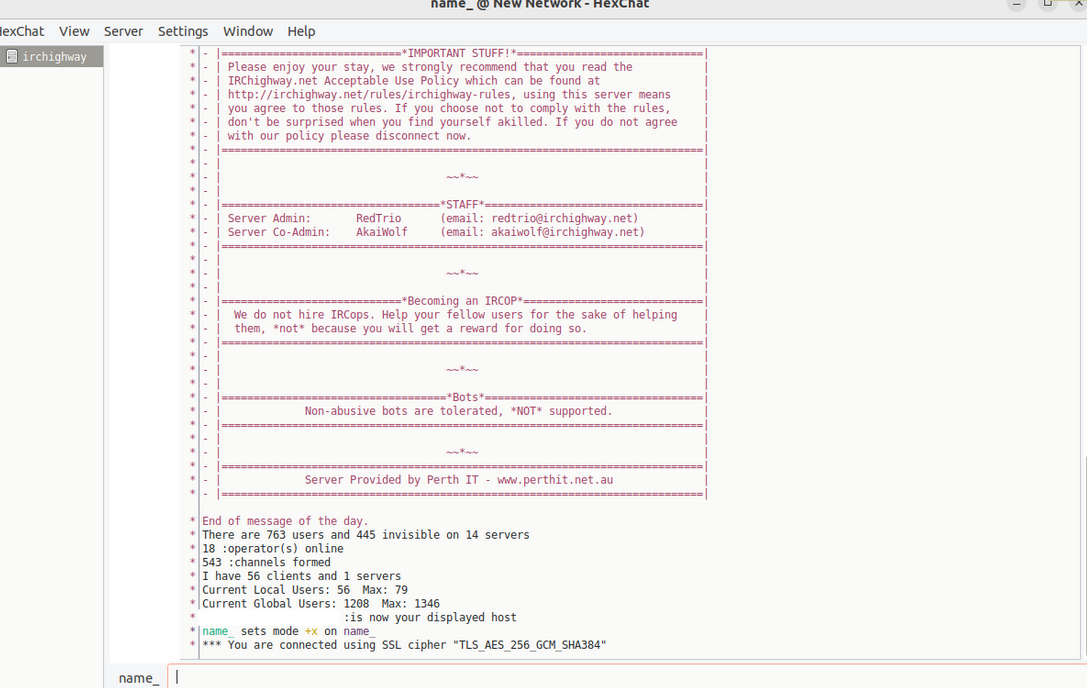
 Extract the text file from the zip file, and then open the text file.
Extract the text file from the zip file, and then open the text file. Identify the book you want to obtain, and then copy the corresponding line of text. In my case, I want to get “Harry Potter and the Chamber of Secrets”, so I will copy the line
Identify the book you want to obtain, and then copy the corresponding line of text. In my case, I want to get “Harry Potter and the Chamber of Secrets”, so I will copy the line  Click on the file, and then click the “Accept” button. The file will then be downloaded to your default downloads folder, and you’ll have it.
Click on the file, and then click the “Accept” button. The file will then be downloaded to your default downloads folder, and you’ll have it.









Now that a sign of a true IRC user
calyx vpn
Thanks for this. Would be awesome to integrate this with readarr.
The IRC bots that run these sharing channels will crap themselves if hit with any kind of automation. Many/most have limited bandwidth and use a queueing system that only serves one or two downloads at a time and a small queue (it varies, some may have a 10 slot queue, some may have 50 or 100).
You can automate this; but you have to make sure that the automation you create is going to respect the ratelimits. I’d recommend something simple like using a command alias or short script written for your specific IRC client.
It’s what I used to do with that sort of thing; and there are plenty of well known Open Source scripts in the wild as well
As an example; I would use mIRC with it’s scripting system and write my own event trigger scripts to automatically request, wait for and then accept the DCC chat requests and route them appropriately in the interface. There were also scripts that helped with getting the lists; unpacking them, and displaying those lists in my client…so I didn’t have to extract the text from the zip myself, and could select what I needed from the bot.
All of this was lightweight automation that was intended not to flood the bot with commands and fed into command queueing modules that let the bots have time to process.
Sometimes in those days you could get actually (+b)anned, Auto/KILL’ed or /(G/K):LINE’ed for causing a bot to crash…so you had to be careful and respectful with regard to scripts.
TL;DR; know your bot, source channel & network rules, and write your own scripts for safety or read any scripts you import in carefully and understand what they’re doing.
Fair. Might be worth going through this process for those books that readarr doesn’t find. I’m using MaM which has most books already.
FWIW I don’t recall ever finding anything obscure on there so I think it’s mostly mainstream stuff.
thanks for the guide!
Man, I’m getting flashbacks to my days running omenserve on undernet. I had no idea people were still doing this! How does the content compare to places like Anna’s archive these days?
They’re nowhere close to something like Anna. They have nice collections but it’s mostly English mainstream stuff.
Ah, good to know. Back in my day, when we had to walk a hundred miles to school in the snow, up hill both ways, IRC was the only place to get ebooks. I’m guessing it’s just the old users clinging on now.
I remember getting movies off irc. Was how I watched Super Troopers.
I never did that, my connection was too slow to want to take up someone’s DCC slot for like a day to get an entire movie. Remember all the frustrating idiots who would share .lit files, but forget to remove the DRM from them?
In most sharing channels you could possibly just report those to the channel ops (@/&/!/~) and get them kicked or devoiced (removing their (+ or %) state depending on the channel)
I don’t know any channel that would put up with people who wasted your time with DRM’ed files back in the day. It’s less problematic now yes; but still something they don’t want people doing…since you have to be signed in as the purchasing account to de-drm something.
Problem was that I usually only discovered the issue when I went to read the book lol
I may or may not have heard of an svcd
Seems like a solved problem. !aa