Xyre
- 3 Posts
- 26 Comments



I get what they’re saying and it may be ‘technically correct’, but the issue is more nuanced than that. In my experience, some trackers have strict requirements or restricted auth tokens (e.g. can’t browse & download from different IPs). Proxying may be the solution, but I’d have to look at how it decides what traffic gets routed where.
There’s some overlap with my torrrents.py and qbitmanage, but some of its other features sound nice. It also led me to Apprise which might be the notifications solution I’ve been looking for!
Some of the arr-scripts already handle syncing the settings. I had to turn them off because it kept overwriting mine, but Recyclarr might be more configurable.
Thanks!
The problem I’ve found is that the services will query indexers and that not all of the trackers allow you to use multiple IPs. This is where I found it easier to make all outbound requests go through the VPN so I didn’t get in trouble. It’s also why I have the Firefox container set up inside the network with it exposed over the local network as a VNC session. So I can browse the sites while maintaining a single IP.
I do have qbittorrent set up with a kill switch on the VPN interface managed by Gluetun.
The server itself is running nothing but the hypervisor. I have a few VMs running on it that makes it easy provision isolated environments. Additionally, it’s made it easy to snapshot a VM before performing maintenance in case I need to roll back. The containers provide isolation from the environment itself in the event of a service gone awry.
Coming from cloud environments where everything is a VM, I’m not sure what issues you’re referring to. The performance penalty is almost non-existent while the benefits are plenty.
The wiki is a great place to start. Also, most of the services have pretty good documentation.
The biggest tip would be to start with Docker. I had originally started running the services directly in the VM, but quickly ran into problems with state getting corrupted somewhere. After enough headaches I switched to Docker. I then had to spend a lot of time remapping all of the files to get it working again. Knowing where the state lives on your filesystem and that the service will always restart from a known point is great. It also makes upgrades or swapping components a breeze.
Everyone has to start somewhere. Just take it slow and do be afraid to make mistakes. Good luck and have fun! 😀
- Xyre to
 English
English - •
- lemmus.org
- •
- 1Y
- •
If you have the time and resources, I highly recommend it. Once it’s all running it becomes mostly a ‘set it and forget it’ situation. You don’t have to remember to scroll through pages of search results to find content. It’ll automatically grab them for you based on your configured quality profile (or upgrade it to better quality). Additionally, you can easily stream it to any devices in our home network (or remote with a VPN).
You don’t have to do it all at once. Start with a single service you’re interested in and slowly add more over time.
For a long time, that was the case. Then the greed nation attacked. Now they’ve reproduced the cable model on the web and more than half of which have terrible clients / infrastructure.
If I could pay for a single service that operated similar to this setup:
- Tell it what I’d like to watch while also displaying similar content for discovery.
- Tracking progress in every show (while not forgetting!).
- Not losing content I have been watching as it’s now in ‘another castle’.
- A single place to view all tracked shows rather than loading each service individually.
I probably would sign up for it as that’s what was so successful for Netflix until all of the studios thought they could do better. And now the consumer has to suffer the consequences.
Good point, updated with HQ link.
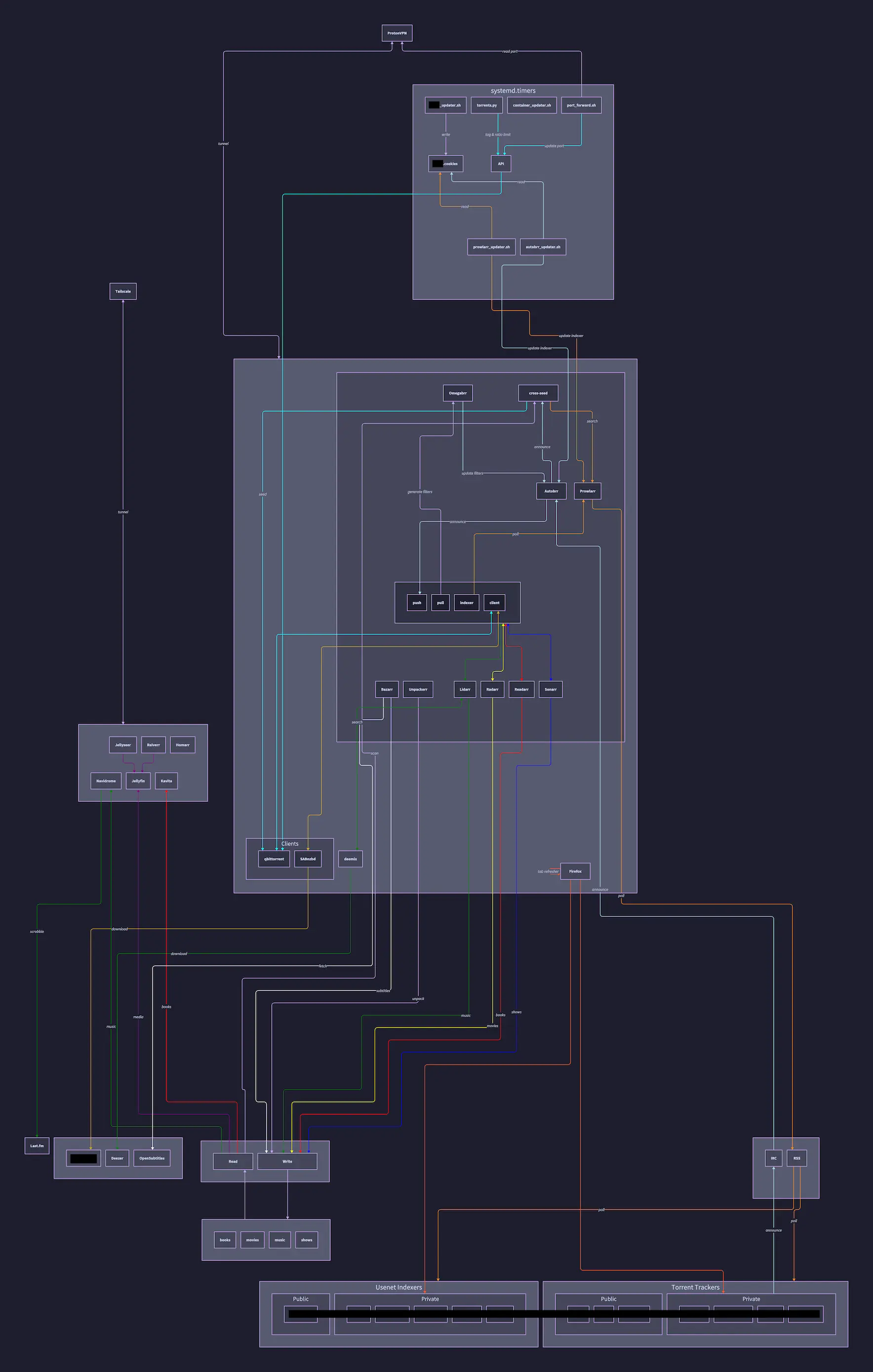
Each service is a separate docker-compose.yml, but they are more-or-less the same as the example configs provided by each service. I did it this way as opposed to a single file to make it easier to add/remove services following this pattern.
I do have a higher quality version of the diagram, but had to downsize it a lot to get pictrs to accept it…
The systemd.timers are basically cronjobs for scripts I wrote to address a few of the pain points I’ve encountered with the setup. They’re either simple curl or wget and jq calls or use Python for more complex logic. The rest are services that are either a part of or adjacent to *arrs.
As for k8s, personally I feel that would add more complexity than it’s worth. I’m not looking for a second job. 😛
I’m just not confident that I’d be able to pass an interview with either of them. No issue with rules or ratios, I simply don’t have enough time to study up on the technicals. I used to be on a decent tracker years ago, but didn’t pay enough attention when they shut down and missed out on the open invites.
I’ve tried RuTracker in the past but it hasn’t worked very well for me so far. Soulseek sounds interesting, especially if they get a Lidarr integration working.
- Xyre to
 English
English - •
- 1Y
- •

{kind=link}
I don’t have any recommendations, but have seen a community for these types of games that may be relevant:
!shmups@lemmus.org