- 0 Posts
- 204 Comments
Neither does Google Trust Services or DigiCert. They’re all HTTP validation on Cloudflare and we have Fortune 100 companies served with LetsEncrypt certs.
I haven’t seen an EV cert in years, browsers stopped caring ages ago. It’s all been domain validated.
LetsEncrypt publicly logs which IP requested a certificate, that’s a lot more than what regular CAs do.
I guess one more to the pile of why everyone hates Zscaler.
That’s more of a general DevOps/server admin steep learning curve than Vaultwarden’s there, to be fair.
It looks a bit complicated at first as Docker isn’t a trivial abstraction, but it’s well worth it once it’s all set up and going. Each container is always the same, and always independent. Vaultwarden per-se isn’t too bad to run without a container, but the same Docker setup can be used for say, Jitsi which is an absolute mess of components to install and make work, some Java stuff, and all. But with Docker? Just docker compose up -d, wait a minute or two and it’s good to go, just need to point your reverse proxy to it.
Why do you need a reverse proxy? Because it’s a centralized location where everything comes in, and instead of having 10 different apps with their own certificates and ports, you have one proxy, one port, and a handful of certificates all managed together so you don’t have to figure out how to make all those apps play together nicely. Caddy is fine, you don’t need NGINX if you use Caddy. There’s also Traefik which lands in between Caddy and NGINX in ease of use. There’s also HAproxy. They all do the same fundamental thing: traffic comes in as HTTPS, it gets the Host header from the request and sends it to the right container as plain HTTP. Well it doesn’t have to work that way specifically but that’s the most common use case in self hosted.
As for your backups, if you used a Docker compose file, the volume data should be in the same directory. But it’s probably using some sort of database so you might want to look into how to do periodic data exports instead, as databases don’t like to be backed up live since the file is always being updated so you can’t really get a proper snapshot of it in one go.
But yeah, try to think of it as an infrastructure investment that makes deploying more apps in the future a breeze. Want to add a NextCloud? Add another docker compose file and start it, Caddy picks it up automagically and boom, it’s live and good to go!
Moving services to a new server is also pretty easy as well. Copy over your configs and composes, and volumes if applicable. Start them all, and they should all get back exactly in the same state as they were on the other box. No services to install and configure, no repos to add, no distro to maintain. All built into the container by someone else so you don’t have to worry about any of it. Each update of the app will bring with it the whole matching updated OS with the right packages in the right versions.
As a DevOps engineer we love the whole thing because I can have a Kubernetes cluster running on a whole rack and be like “here’s the apps I want you to run” and it just figures itself out, automatically balances the load, if a server goes down the containers respawn on another one and keeps going as if nothing happened. We don’t have to manually log into any of those servers to install services to run an app. More upfront work for minimal work afterwards.


Yeah, that didn’t stop it from pwning a good chunk of the Internet: https://en.wikipedia.org/wiki/Log4Shell
IMO the biggest attack vector there would be a Minecraft exploit like log4j, so the most important part to me would make sure the game server is properly sandboxed just in case. Start from a point of view of, the attacker breached Minecraft and has shell access to that user. What can they do from there? Ideally, nothing useful other than maybe running a crypto miner. Don’t reuse passwords obviously.
With systemd, I’d use the various Protect* directives like ProtectHome, ProtectSystem=full, or failing that, a container (Docker, Podman, LXC, manually, there’s options). Just a bare Alpine container with Java would be pretty ideal, as you can’t exploit sudo or some other SUID binaries if they don’t exist in the first place.
That said the WireGuard solution is ideal because it limits potential attackers to people you handed a key, so at least you’d know who breached you.
I’ve fogotten Minecraft servers online and really nothing happened whatsoever.
If your stuff is all Docker then yeah, immutable makes sense as it makes the entire box declarative and immutable: you can get back the exact same operating Docker environment on the server, and then you can get back the exact same Docker workloads going with the Docker compose configurations.
If you ever need to run stuff you’d run on Debian, you can just shove it in a Debian container.
That said, if most of the stuff is containers, the risk of just the core Debian breaking is fairly low. Pick whatever is easiest for you to deal with based on your needs. Immutable distros have a bit of a learning curve.
I learned it accidentally trying to get root on an encrypted dataset working with systemd init without sd-zfs. This turns out to be how the zfs utility works internally to signal the driver “hey it’s okay, I’m a ZFS utility the user isn’t using mount directly”, and how you deal with mounting your root dataset to the temporary /sysroot while having its mountpoint set to / while in initramfs before pivoting root.
Obviously, don’t use that other than recovering your data, if you want to use this array you should figure out the mountpoints properly so ZFS does it automatically. It shouldn’t break anything but it’s gross, either set mointpoint=legacy and use fstab or set its mountpoint in ZFS and use zfs mount.
The trick for this one is mount -t zfs -o zfsutil internal /mnt/some/path
Assuming the root dataset is mountable. If you have a -o canmount=off on the dataset it will refuse to mount.
If it’s -o mountpoint=legacy then you don’t need -o zfsutil, but still need to provide both the source and destination paths. Otherwise you’ll get the fstab error because mount can’t figure out what to mount or where to mount it.
Yep there’s a reason I reached directly for that configuration. WireGuard uses UDP, that’s one of the first things that gets blocked.
Turns out that’s also the kind of protocol corporate VPNs use, reusing port 443 over TCP. They call those “SSL VPN”. They get to weed out all commercial VPNs used to bypass their firewalls as well as most torrent/game activity while still mostly catering to their business guests.
Best bet is probably going to be using something like OpenVPN on port 443 in TCP mode, which basically looks like regular HTTPS. It’s a hotel, I doubt they’re going to be doing deep analysis to detect signs it’s OpenVPN. It’s detectable easily but they wouldn’t spend the money on that advanced of a firewall.
My guess is they went for an allowed list of ports rather than blocked, so it lets DNS (53), HTTP (80), HTTPS (443), probably also POP/IMAP/SMTP (110, 995, 143, 993, 465)
I wish Jitsi was actually good. It’s a pain in the ass to setup and I’ve yet to get anything more than maybe 480p on it across both Firefox and Chome as well as the mobile apps on iOS and Android. It even reports poor internet connection when the server is literally 5ms away over the Internet, so even if it has to fall back to routed traffic I’ve still got a full gigabit of connectivity between me and my server in a datacenter which is way more than enough. None of the open instances I tried were any different either.
It feels like a ridiculously overcomplicated WebRTC demo app, the end performance is essentially identical.
Separate components that do one thing and only that thing and does it well are good. Extra containers are basically free.
- The exporters provide the metrics. They can be standalone executables like the node exporter, can also be included in apps themselves easily since it’s just HTTP. It’s trivial to add metrics to just about anything without needing extra ports. Its protocol is also easier and more efficient than SNMP.
- Prometheus scrapes those metrics and stores it into its database. In other apps that’d be the role things like PostgreSQL have: you don’t really use it directly, but it’s no less important.
- Grafana is the frontend you slap in front of Prometheus to actually display your metrics.
- Alertmanager looks at the metrics and sends alerts. It’s separate because if your Prometheus box goes down, how are you gonna be alerted of that?
All 4 of those can be swapped with something else equivalent and it all still works. Don’t like the UI? Replace Grafana. Don’t like Prometheus? There’s VictoriaMetrics and InfluxDB
It looks silly on a small scale, but it scales up very well. Couple hundred VMs per Prometheus install, node exporters on every VM and a single Grafana cluster to visualize the data for the whole infrastructure at once.
That makes it all well liked in enterprise which means there are exporters for damn near anything (even the Lemmy server has a built-in exporter I can scrape with Prometheus), which in turn makes it the easy solution for self-hosters too, and here we are.
I feel like it’s easier to set up than some of the all in one solutions I’ve used previously, despite being several components. They’re all components that basically just work out of the box.
I’ll parrot the top reply from Reddit on that one: to me, self hosting starts as a learning journey. There’s no right or wrong way, if anything I intentionally do whacky weird things to test the limits of my knowledge. The mistakes and troubles are when you learn. You don’t really understand the significance of good backups until you had to restore from them.
Even in production, it differs wildly. I have customers whom I set up a bare metal Ubuntu in some datacenter for cheap, they’ve been running on that setup for 10 years. Small mom and pop shop, they will never need a whole cluster of machines. Then at my day job we’re looking at things like Kubernetes and very heavyweight stacks because we handle a lot of traffic.
Some people self-host a PiHole on a Raspberry Pi and that’s all they need. Some people have entire NAS setups with smart TVs accessing their Plex/Jellyfin servers for the whole extended family. I host my own emails, which is a pain in the ass to get working reliably and clean your IP reputation.
I guess the only thing you should know is, you need some time to commit to maintaining your stuff if you don’t want it to break or get breached (if exposed to the Internet), and a willingness to learn because self hosting isn’t a turnkey experience. It can be a turnkey installation but when your SD card/drives fails you’re still on your own to troubleshoot and fix it. You don’t set a NextCloud server to replace Google Drive with the expectation that you shove the server in a closet forever. Owning your infrastructure and data comes at a small but very important upkeep time investment.
It depends on what you use on the Python side. Classically that would have been uWSGI or one of the *SGI interfaces, and lately ASGI.
Sure, one can totally make Python apps that serve HTTP directly. The same can be done with PHP (and Ruby and others) as well, but most people still run their PHP through PHP-FPM over FastCGI because you can offload a lot of the work to the much faster NGINX side. A fair amount of apps make use of X-Accel-Redirect to serve private files, so you don’t tie up a PHP worker for an hour serving the user’s 2GB file.
But yes, as those languages all move to async computing and away from worker pools, it’s more common to see those serve HTTP directly, and there’s less and less need for a proxy that supports those other protocols. The async event loop is what made NGINX special when it came out, so naturally languages that moves to that model greatly reduce the need for that as well, they too can easily handle thousands of concurrent connections no problems. Plus these days people slap a CDN in front anyway so static file performance doesn’t matter quite as much.
NGINX can really do a lot of things out of the box while being pretty easy to configure. NGINX can serve static files, it can proxy emails, it can do FastCGI, it can do UWSGI, it can do HTTP proxying, you can run Lua code inside NGINX to do things, there’s a module for RTMP live streaming. You can also implement some stuff like external authentication to protect your services/authenticate them at the proxy level. It can also do caching. Not all that useful with all those Rust and Go apps with their own built-in web server but if you run large legacy apps at scale it’s great, you can offload a lot of stuff away from your slow ass PHP app.
Caddy’s simpler but the current battle tested popular option is NGINX.
HAproxy is good at what it does but it’s only good at proxying and simple rules. For the most part, it’s used as a load balancer and router and doesn’t really process the requests itself. It can alter some things in it but it’s limited, and it only does HTTP and TCP. So you can’t really run PHP or Python or Ruby or whatever applications directly behind HAproxy. That makes NGINX a better choice there because NGINX deals with HTTP and only passes the request details to the application which doesn’t have to do HTTP on its own. I usually see HAproxy load balancing to NGINX hosts with some PHP/Python/Ruby app behind them.
Apache is old. It’s gotten better but the way it works just doesn’t reflect most modern use cases. I remember when NGINX popped off like 15 years ago and just how much more resource efficient it was and how happy I was with the upgrade. So it exists and still works but not very popular anymore. It’s a bit easier to set up but also a bit weird with things like mod_php which runs directly inside Apache instead of a dedicated user that can be better sandboxed.
Traefik is getting traction in big part because it fits well with the Docker ecosystem and just sets itself up automatically.
There’s also Envoy if you want some serious proxying and meshing but setting that one up is truely headache inducing.
They’re all pretty good web servers regardless, it comes down to preference. There’s no right choice because everyone’s needs are different.
The problem with this is the probability of your server being available for the next retry is fairly low.
Usually some sort of exponential backoff is used so it might retry after 5 minutes, 15 minutes, an hour, 3 hours, 6 hours, 24 hours, 48 hours, give up.
6-8 hours is probably too much for anything serious where you don’t want emails to just drop. It will work so if you’re just using it to sign up to sites and stuff, you can make sure your server is on to receive the verification emails and stuff. But I wouldn’t use it for anything important.

Depends on how good the ISP router is. I’ve had one that had most of the advanced settings available, so I didn’t feel the need to change. For a while I had offloaded DHCP and DNS and VPN to a Raspberry Pi. It’s very much possible to make do with the ISP router. That ISP would let you passthrough the public IP to a box on your network which lets you do a lot of stuff without going into bridge mode, so I could make my server the target while still letting the router do the routing so if my server was down it didn’t take the whole network with it.
Then I got a bad one where it won’t even let you set up port forwards unless the device is registered over DHCP so my static stuff and VMs didn’t work. Got my EdgeRouter X back online to get my stuff done.
I do use VLANs and stuff now so it makes sense for me to use my own router. With everything getting breached these days, I have a VLAN just for my computers, another one for smart but trusted-ish devices (the TV’s gotta reach the NAS), one for IoT that’s completely shielded off.
What you’re missing out on depends a lot on what features you don’t have you could make use of. If you have like 3 devices using the network like I did when I lived alone, yeah you’re probably not going to miss out on the VLANs. But maybe you want to do ad blocking network-wide. Maybe you’d want to better prioritize interactive traffic like VoIP and video calls or games. Maybe you want a reverse proxy or VPN that works even if your home server is down. Maybe you want your kids to not hog all the bandwidth. There’s a lot of things a router can do.
So if the ISP router does everything you want and you’re happy with its performance, it’s fine. Just keep it in mind, when you start being like “I wish it had X and Y features” maybe consider an upgrade then.
If you have the option of not getting a router from your ISP, I would definitely recommend bringing your own. If they provide it regardless and you’d be replacing it through unofficial means, eh, if it works well…


I have none of that on my phone, just plain old keyboard.
But the reason it’s everywhere is it’s the new hot thing and every company in the world feels like they have to get on board now or they’ll be potentially left behind, can’t let anyone have a headstart. It’s incredibly dumb and shortsighted but since actually innovating in features is hard and AI is cheap to implement, that’s what every company goes for.
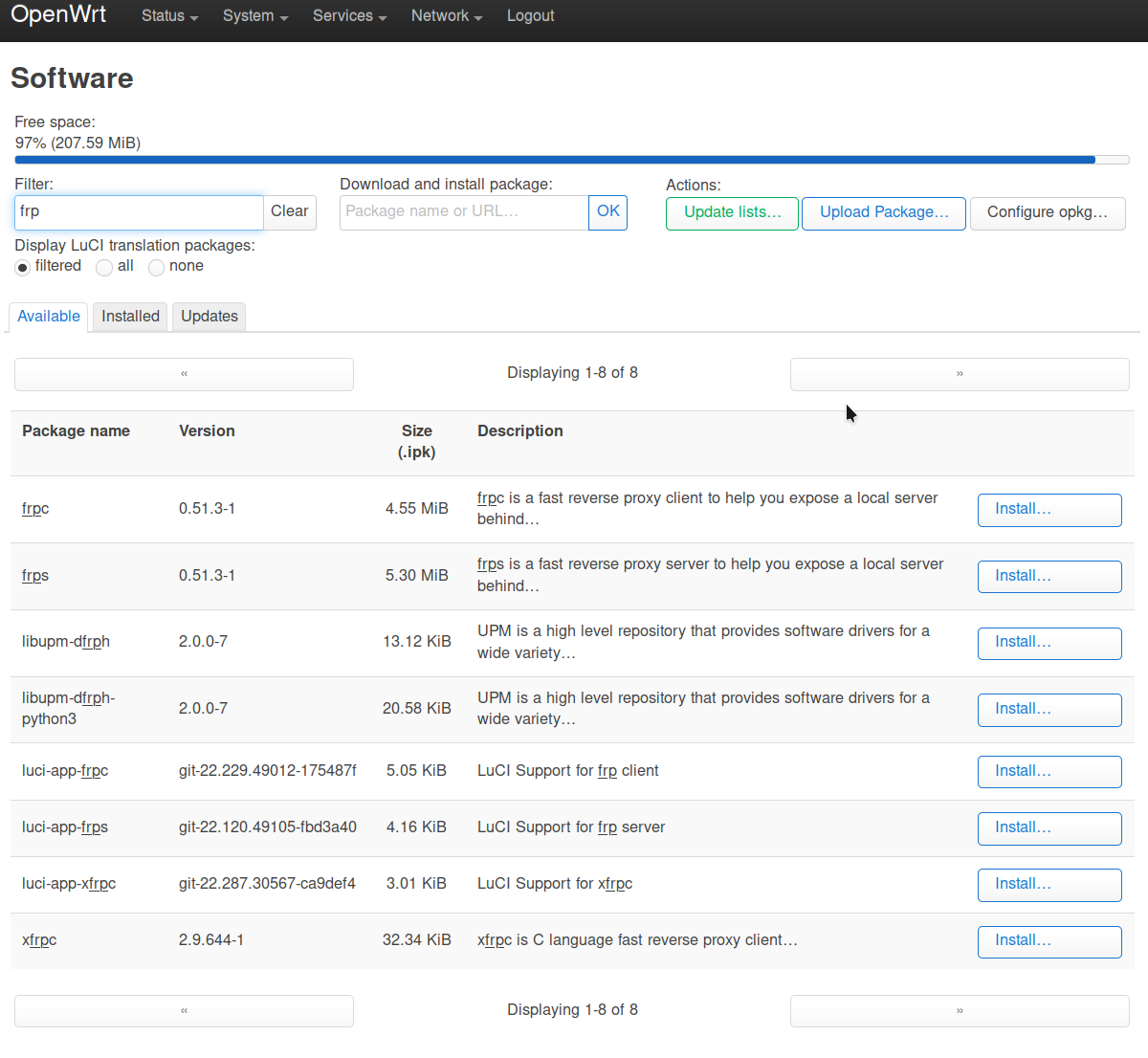
If you want FRP, why not just install FRP? It even has a LuCI app to control it from what it looks like.
NGINX is also available at a mere 1kb in size for the slim version, full version also available as well as HAproxy. Those will have you more than covered, and support SSL.
Looks like there’s also acme.sh support, with a matching LuCI app that can handle your SSL certificate situation as well.
The concern for the specific disk technology is usually around the use case. For example, surveillance drives you expect to be able to continuously write to 24/7 but not at crazy high speeds, maybe you can expect slow seek times or whatever. Gaming drives I would assume are disposable and just good value for storage size as you can just redownload your steam games. A NAS drive will be a little bit more expensive because it’s assumed to be for backups and data storage.
That said in all cases if you use them with proper redundancy like RAIDZ or RAID1 (bleh) it’s kind of whatever, you just replace them as they die. They’ll all do the same, just not with quite the same performance profile.
Things you can check are seek times / latency, throughput both on sequential and random access, and estimated lifespan.
I keep hearing good things about decomissioned HGST enterprise drives on eBay, they’re really cheap.

Genuine political dissent would become logistically impossible, and virtual mob rule a certainty.
There’s a major difference between political dissent and hate speech.
You can say: “I don’t think transgender people should be allowed to choose which bathroom they go to”, that just makes you a shitty person with no compassion. But if you say “If I see a trans women in the mens bathroom I’ll beat them up out of there”, that is very clearly hate speech and threats of violence.
It’s not like it’s hard to treat people with basic respect. You can disagree without resorting to hateful comments and threats and name calling. If you don’t see the hate speech problem you’re probably part of the problem because surprise, it’s only conservatives you see online constantly spewing FUD and hate speech.
That, and they also either renovate in pseudo-luxery or build fairly luxurious condos in a world of HOAs going absolutely out of control and making sure you can’t actually live in there even if you could afford it because your next door karen will file a noise complaint every time you flush the toilet.
Number of constructions I’ve seen actually designed to be affordable in the last couple years: zero. None. They all target rich people that could afford a normal house anyway.
Even new apartment buildings, the thing that people that can’t get a mortgage get, is now also all designed for 3000+ monthly rents.
Property developers are greedy pigs.
Have they tried building average, affordable condos instead of luxury condos?
All the new condo developments I’ve been seeing everywhere are more expensive than a townhouse nearby, and half the size of nearby apartments that are also half what the mortgage would be on a 1-2M fucking condo.
Pretty sure they can do away without the penthouse pool and hot tub and bring the price down, but it wouldn’t be nearly as profitable for them so they won’t.
Nobody is actually trying to help lower home prices because everyone’s retirement plan depends on houses being unaffordable.
I’ll never understand the people that fake these kinds of things. Fake watches, fake followers, fake views, fake likes, fake jobs. Why?
What’s attractive about likes and views anyway? Why would I care that my date has 0 followers or a million followers? If anything it means they’ll constantly be busy streaming.
It could be a disk slowly failing but not throwing errors yet. Some drives really do their best to hide that they’re failing. So even a passing SMART test I would take with some salt.
I would start by making sure you have good recent backups ASAP.
You can test the drive performance by shutting down all VMs and using tools like fio to do some disk benchmarking. It could be a VM causing it. If it’s an HDD in particular, the random reads and writes from VMs can really cause seek latency to shoot way up. Could be as simple as a service logging some warnings due to junk incoming traffic, or an update that added some more info logs, etc.
There’s always the command escape hatch. Ultimately the roles you’ll use will probably do the same. Even a plugin would do the same, all the ZFS tooling eventually shells to the zfs/zpool, probably same with btrfs. Those are just very complex filesystems, it would be unreliable to reimplement them in Python.
We use tools to solve problems, not make it harder for no reason. That’s why command/shell actions exist: sometimes it’s just better to go that way.
You can always make your own plugin for it, but you’re still just writing extra code to eventually still shell out into the commands and parse their output.
The whole chanting the “axe the tax” to Québec where we don’t even have the carbon tax was all I needed. Even if we had it, with all our hydro we wouldn’t pay much carbon tax anyway.
He’s still managed to convince a ton of the rural population that’s true and that he’ll make gas so much cheaper and their profits skyrocket.
Very minimal. Mostly just run updates every now and then and fix what breaks which is relatively rare. The Docker stacks in particular are quite painless.
Couple websites, Lemmy, Matrix, a whole email stack, DNS, IRC bouncer, NextCloud, WireGuard, Jitsi, a Minecraft server and I believe that’s about it?
I’m a DevOps engineer at work, managing 2k+ VMs that I can more than keep up with. I’d say it varies more with experience and how it’s set up than how much you manage. When you use Ansible and Terraform and Kubernetes, the count of servers and services isn’t really important. One, five, ten, a thousand servers, it matters very little since you just run Ansible on them and 5 minutes later it’s all up and running. I don’t use that for my own servers out of laziness but still, I set most of that stuff 10 years ago and it’s still happily humming along just fine.
LetsEncrypt certs are DV certs. That a put a TXT record for LetsEncrypt vs a TXT record for a paid DigiCert makes no difference whatsoever.
I just checked and Shopify uses a LetsEncrypt cert, so that’s a big one that uses the plebian certs.