Justin
(Justin)
Tech nerd from Sweden
- 1 Post
- 156 Comments
You should use synapse. Dendrite is not intended for self-hosted homeservers. You will have an easier time with calling/rtc with synapse as well.
Here is a good example of how to set up a home server, which was shown off by the devs at fosdem last weekend:

Of the services OP is asking about, I’ve only run Lemmy, but I will say that running fediverse services are quite advanced, which is exactly what k8s is made for - Running advanced web applications.
I’m firmly on the “k8s at any scale” team. If you can figure out how to run the k3s install command and are willing to look at some yaml documentation, you will have a much easier time setting up database and networking, running backups, porting your infrastructure to other providers, and maintaining everything, than with legacy control panels or docker compose. The main reason why Docker Compose is so much more accessible for self-hosters is because of the quantity of noob-focused documentation for Docker Compose, But learning either system requires learning the same concepts of containers, IP adresses, storage, etc. Docker Compose also has some disk and networking shortcuts for single-server workloads, but they also have their downsides (what is a macvlan?).
The main reason why I think Kubernetes is critical for this specific workload is the number of production-critical databases that OP will need to run. OP will be running something like 4-8 postgres databases, with high uptime and 100% durability requirements. Trying to do that manually with Docker compose just isn’t feasible unless you’re willing to code. Kubernetes makes all of that automated with CNPG. See how easy it is to create a database and have automated backups to S3 with Kubernetes
The biggest challenge for kubernetes is probably that the smaller applications don’t come with example configs for Kubernetes. I only see mastodon having one officially. Still, I’ve provided my config for Lemmy, and there are docker containers available for Friendica and mbin (though docker isn’t officially supported for these two). I’m happy to help give yaml examples for the installation of the applications.
I would recommend installing k3s and cnpg on the VPS. These will make it easier to run the various containers and databases you will need to run lemmy, etc. This is the standard way that big companies run servers in 2025, and it’s 100% portable to any server/hosting company just through copying and pasting the yaml files (like docker compose).
https://docs.k3s.io/quick-start
https://cloudnative-pg.io/documentation/1.25/quickstart/
Make sure you save backups of your VPS, and use object storage to backup your databases.
I have example kubernetes configuration for lemmy on my Git. It doesn’t use any volumes/local-storage, all user data is saved into either the database or object storage, to make it cheap and easy to backup.
I’m a professional DevOps engineer, so I work with hosting every day. Let me know if you have any questions or want advice.

Ah ok, I didn’t catch that. Other articles were discussing v3’s training using only 2.8M GPU hours.
https://www.ft.com/content/c82933fe-be28-463b-8336-d71a2ff5bbbf
It should also be pretty obvious that this is following the usual Chinese MO of using massive state subsidies to destroy the international competition with impossibly low dumping prices. We are seeing this in all sorts of sectors.
In this case, DeepSeek is announcing the training time for their LLMl, which wall street is extrapolating costs from. No state aid involved.
Oh definitely, everything in kubernetes can be explained (and implemented) with decades-old technology.
The reason why Kubernetes is so special is that it automates it all in a very standardized way. All the vendors come together and support a single API for management which is very easy to write automation for.
There’s standard, well-documented “wizards” for creating databases, load-balancers, firewalls, WAFs, reverse proxies, etc. And the management for your containers is extremely robust and extensive with features like automated replicas, health checks, self-healing, 10 different kinds of storage drivers, cpu/memory/disk/gpu allocation, and declarative mountable config files. All of that on top of an extremely secure and standardized API.
With regard for eBPF being used for load-balancers, the company who writes that software, Isovalent, is one of the main maintainers of eBPF in the kernel. A lot of it was written just to support their Kubernetes Cilium CNI. It’s used, mainly, so that you can have systems with hundreds or thousands of containers on a single node, each with their own IP address and firewall, etc. IPtables was used for this before. But it started hitting a performance bottleneck for many systems. Everything is automated for you and open-source, so all the ops engineers benefit from the development work of the Isovalent team.
It definitely moves fast, though. I go to kubecon every year, and every year there’s a whole new set of technologies that were written in the last year lol
Ah, but your dns discovery and fail over isn’t using the built-in kubernetes Services? Is the nginx using Ingress-nginx or is it custom?
I would definitely look into Ingress or api-gateway, as these are two standards that the kubernetes developers are promoting for reverse proxies. Ingress is older and has more features for things like authentication, but API Gateway is more portable. Both APIs are implemented by a number of implementations, like Nginx, Traefik, Istio, and Project Contour.
It may also be worth creating a second Kubernetes cluster if you’re going to be migrating all the services. Flannel is quite old, and there are newer CNIs like Cilium that offer a lot more features like ebpf, ipv6, Wireguard, tracing, etc. (Cilium’s implementation of the Gateway API is bugger than other implementations though) Cillium is shaping up to be the new standard networking plugin for Kubernetes, and even Red Hat and AWS are starting to adopt it over their proprietary CNIs.
If you guys are in Europe and are looking for consultants, I freelance, and my employer also has a lot of Kubernetes consulting expertise.
All containers in a pod share an IP, so you can just use localhost: https://www.baeldung.com/ops/kubernetes-pods-sidecar-containers
Between pods, the universal pattern is to add a Service for your pod(s), and just use the name of the service to connect to the pods the Service is tracking. Internally, the Service is a load-balancer, running on top of Kube-Proxy, or Cilium eBPF, and it tracks all the pods that match the correct labels. It also takes advantage of the Kubelet’s health checks to connect/disconnect dying pods. Kubedns/coredns resolves DNS names for all of the Services in the cluster, so you never have to use raw IP addresses in Kubernetes.
Go all out and register your container IPs on your router with BGP 😁
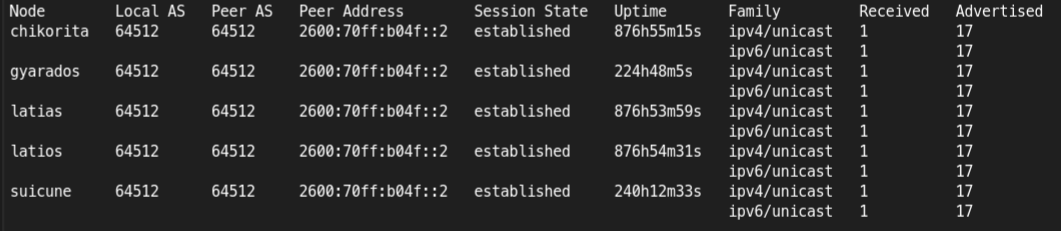
(This comment was sent over a route my automation created with BGP)
I’ve inherited it on production systems before, automated service discovery and certificate renewal is definitely what admins should have in 2025. I thought the label/annotation system it used on Docker had some ergonomics/documentation issues, but nothing serious.
It feels like it’s more meant for Docker/Podman though. On Kubernetes I use cert-manager and Gateway API+Project Contour. It does seem like Traefik has support for Gateway API too, so it’s probably a good choice for Kubernetes too?
Maybe crowdsec could add a list for blocking scraping for LLMs

Nope, you don’t need any VPS to use it, it comes with an SFTP interface.
https://www.hetzner.com/storage/storage-box/
offsite backup for $2/TB and no download fees, 1/3rd the price of B2.
Hardware-wise:
- Reorganize my networking closet and rack up my switches
- Replace my core switch with 10 gbit, connect up 10Gbit fiber to my laptop dock and one of my nodes still on copper
- Add 3 more nodes to my cluster with nvme storage so that I can start an erasure-coding pool in ceph.
Software wise, too many projects to count lol
Renovate is a very useful tool for automatically updating containers. It just watches a git repo and automatically updates stuff.
I have it configured to automatically deploy minor updates, and for bigger updates, it opens a pull request and sends me an email.
Yeah full VMs are pretty old school, there are a lot more management options and automation available with containers. Not to mention the compute overhead.
Red Hat doesn’t even recommend businesses to use VMs anymore, and they offer a virtualization tool that runs the VMs inside a container for legacy apps. Its called Openshift Virtualization.
You should keep your docker/kubernetes configuration saved in git, and then have something like rclone take daily backups of all your data to something like a hetzner storage box. That is the setup I have.
My entire kubernetes configuration: https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications
My backup cronjob: https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications/backups/rclone-velero.yaml
With something like this, your entire setup could crash and burn, and you would still have everything you need to restore safely stored offsite.
RAM is definitely the limiting factor. The one server with a 5600X and 64GiB ram handled it pretty well as long as I wasn’t doing cpu transcoding, though.
I’ve since added two N100 boxes with 16GiB and two first gen Epyc 32 cores with 64GiB ram. All pretty cost effective and quiet.
The N100 CPUs get overloaded sometimes if they’re running too many databases, but usually it balances pretty well.
- Justin to
 English
English - •
- 1Y
- •
All storage is on a Ceph cluster with 2 or 3 disk/node replication. Files and databases are backed up using Velero and Barman to S3-compatible storage on the same cluster for versioning. Every night, those S3 buckets are synced and encrypted using rclone to a 10tb Hetzner Storage Box that keeps weekly snapshots.
Config files in my git repo:
https://codeberg.org/jlh/h5b/src/branch/main/argo/external_applications/velero-helm.yaml
https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications/bitwarden/database.yaml
https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications/backups
https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications/rook-ceph
Bit more than 3 copies, but hdd storage is cheap. Majority of my storage is Jellyfin anyways, which doesn’t get backed up.
I’m working on setting up some small nvme nodes for the ceph cluster, which will allow me to move my nextcloud from hdd storage into its own S3 bucket with 4+2 erasure coding (aka raid 6). That will make it much faster and also its cut raw storage usage from 4x to 1.5x usable capacity