The temperature scale, I think. You divide the logit output by the temperature before feeding it to the softmax function. Larger (resp. smaller) temperature results in a higher (resp. lower) entropy distribution.
Each row in the figure is a probability distribution over possible outputs (x-axis labels). The more yellow, the more likely (see the colour map on the right). With a small temperature (e.g., last row), all the probability mass is on 42. This is a low entropy distribution because if you sample from it you’ll constantly get 42, so no randomness whatsoever (think entropy as a measure of randomness/chaos). As temperature increases (rows closer to the first/topmost one), 42 is still the most likely output, but the probability mass gets dispersed to other possible outputs too (other outputs get a bit more yellow), resulting in higher entropy distributions. Sampling from such distribution gives you more random outputs (42 would still be frequent, but you’d get 37 or others too occasionally). Hopefully this is clearer.
Someone in another reply uses the word “creativity” to describe the effect of temperature scaling. The more commonly used term in the literature is “diversity”.
You are not logged in. However you can subscribe from another Fediverse account, for example Lemmy or Mastodon. To do this, paste the following into the search field of your instance: !technology@beehaw.org
A nice place to discuss rumors, happenings, innovations, and challenges in the technology sphere. We also welcome discussions on the intersections of technology and society. If it’s technological news or discussion of technology, it probably belongs here.
Remember the overriding ethos on Beehaw: Be(e) Nice. Each user you encounter here is a person, and should be treated with kindness (even if they’re wrong, or use a Linux distro you don’t like). Personal attacks will not be tolerated.
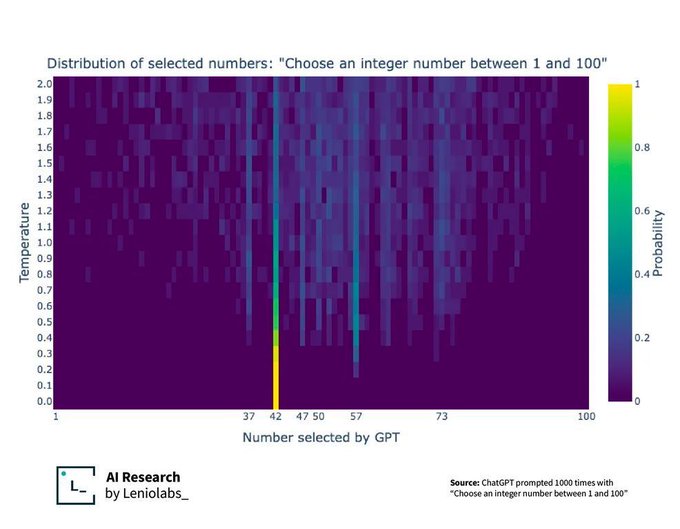








The temperature scale, I think. You divide the logit output by the temperature before feeding it to the softmax function. Larger (resp. smaller) temperature results in a higher (resp. lower) entropy distribution.
I still don’t understand.
Each row in the figure is a probability distribution over possible outputs (x-axis labels). The more yellow, the more likely (see the colour map on the right). With a small temperature (e.g., last row), all the probability mass is on 42. This is a low entropy distribution because if you sample from it you’ll constantly get 42, so no randomness whatsoever (think entropy as a measure of randomness/chaos). As temperature increases (rows closer to the first/topmost one), 42 is still the most likely output, but the probability mass gets dispersed to other possible outputs too (other outputs get a bit more yellow), resulting in higher entropy distributions. Sampling from such distribution gives you more random outputs (42 would still be frequent, but you’d get 37 or others too occasionally). Hopefully this is clearer.
Someone in another reply uses the word “creativity” to describe the effect of temperature scaling. The more commonly used term in the literature is “diversity”.
More yellow more common, more blue less common
I don’t understand any of these words, I need to take a math class or something
Higher temperature -> more chaotic output